1c. Baseline the data#
The next step is to baseline the data in order to get an understanding of what the environment looks like under normal conditions (assuming a breach has not already occurred). This also highlights relationships between systems and networks, such as activity to the internet.
These should also be considered progressive steps, meaning the observations should align with expectations built from outcomes of the previous steps. If they do not reconcile as expected, it could mean a gap exists across one or more of these initial steps.
Some considerations for baselining this data include:
The relative size of data per logical or discrete sets or logical groupings
Trend analysis per: hosts, users, networks, etc.
Catalog processes, IPs, domains, etc (overall and per host / user)
Presently triggering alerts at the onset of this process
New Terms and Threshold rules can be leveraged to assist with this
Observing for generic statistical anomalies
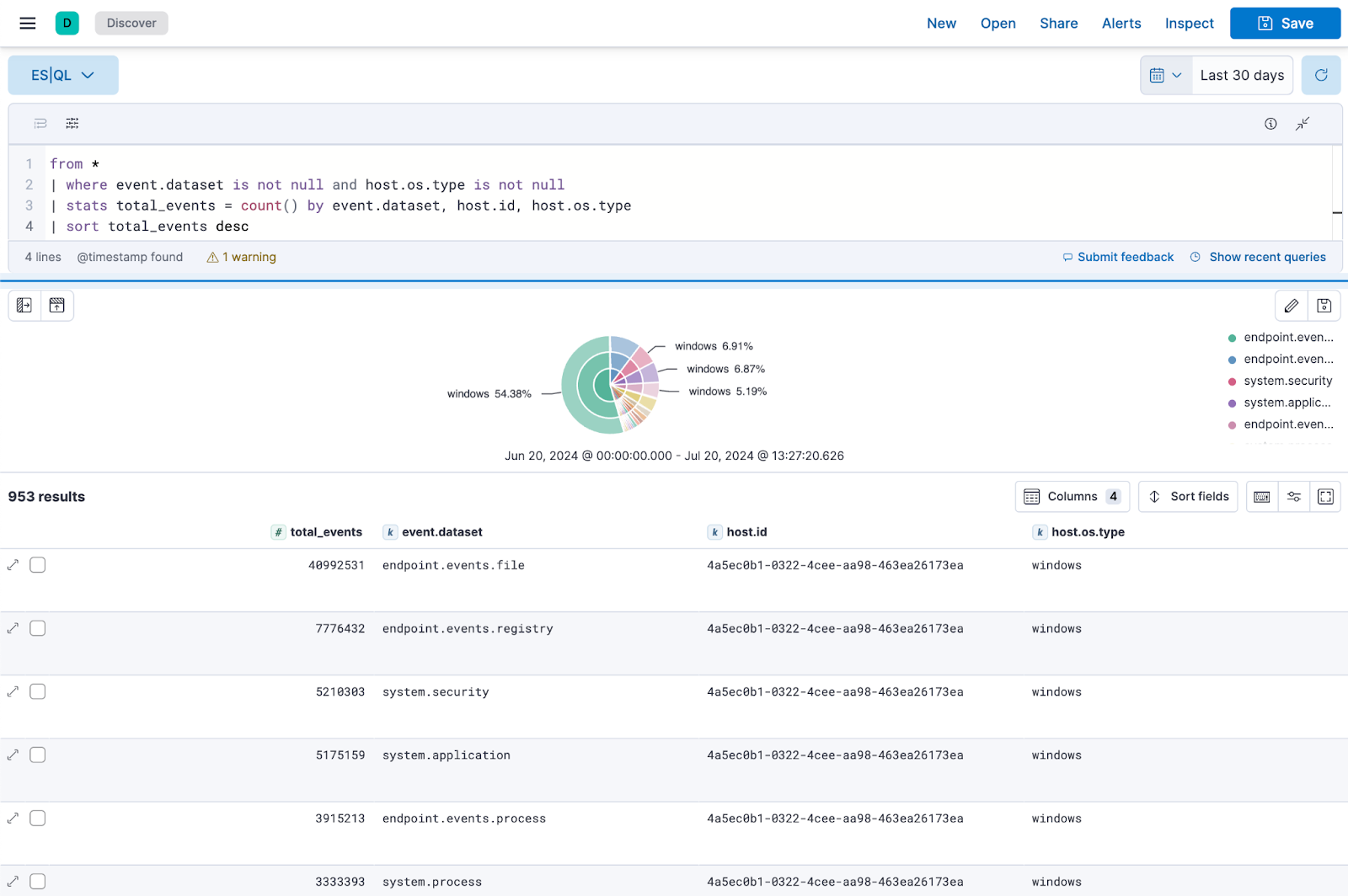
Fig. 4 Baselining total events by dataset, host, and OS in Elastic#
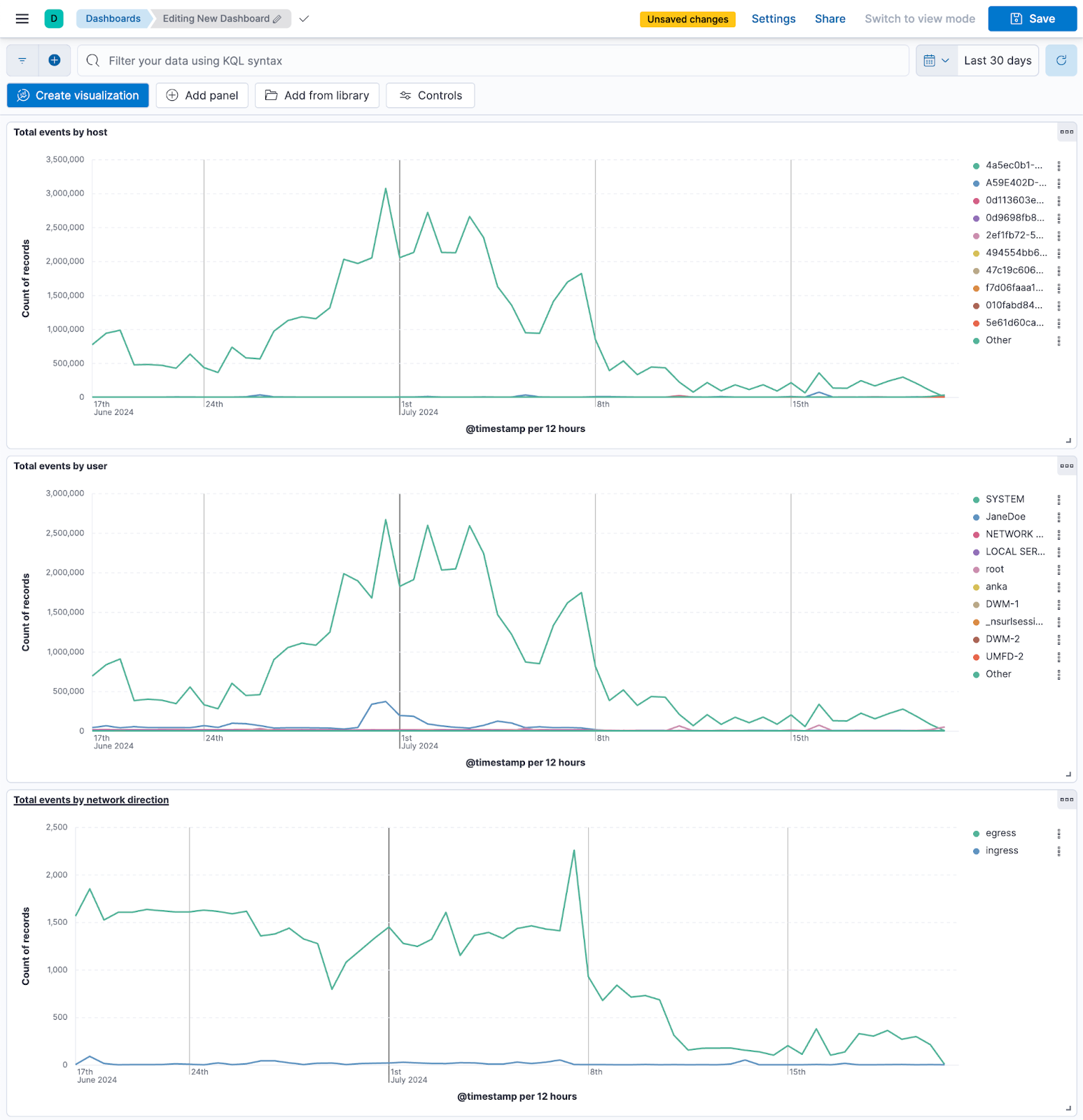
Fig. 5 Trend analysis dashboard for host, users, and network direction#
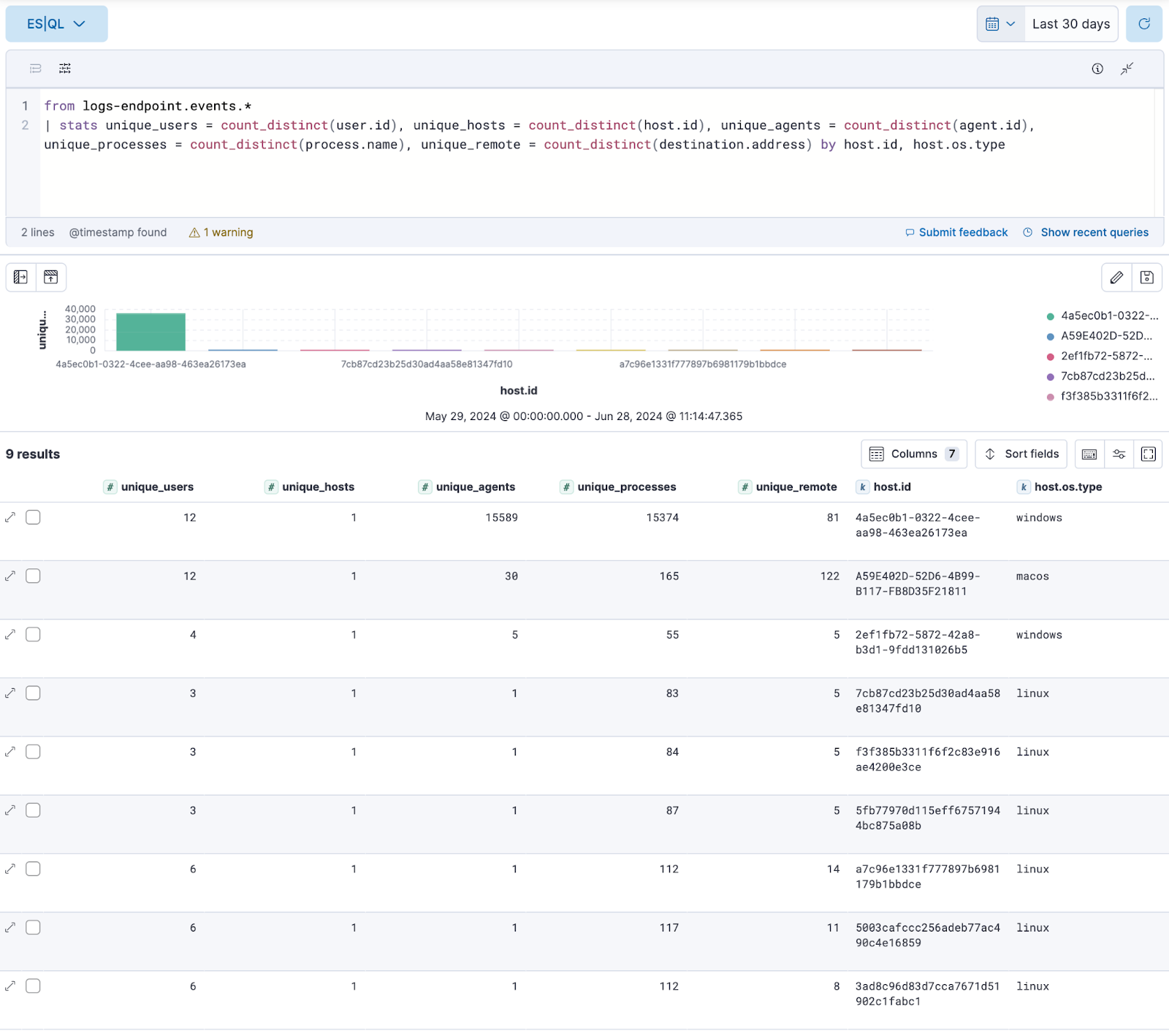
Fig. 6 Baselining total unique counts for various properties by host and OS#
The process of preservation, refreshing, and re-baselining as individual steps was always very challenging, so to see this evolution heading towards a more unified and feasible process is a welcome one. Specifically, this process has evolved due to:
The reduction in cost of storage along with the addition of tiered storage (hot, warm, and cold) which allows for significantly longer storage
Machine learning, clustering, and specifically unlabelled approaches
New terms alerting and identification at the field level (which can also apply to newly seen assets)
Entity analytics technologies
Dynamic and discoverable asset inventories within logging platforms as a feature