3d. Monitor | triage#
Product teams would next need to monitor incoming telemetry and metrics of the released content, whereas operational teams would need to focus on the triggering of alerts within their own environment. In both cases, it is mostly alerting which is being consumed, however, they will come from different sources and have different responsibilities for managing their observations.
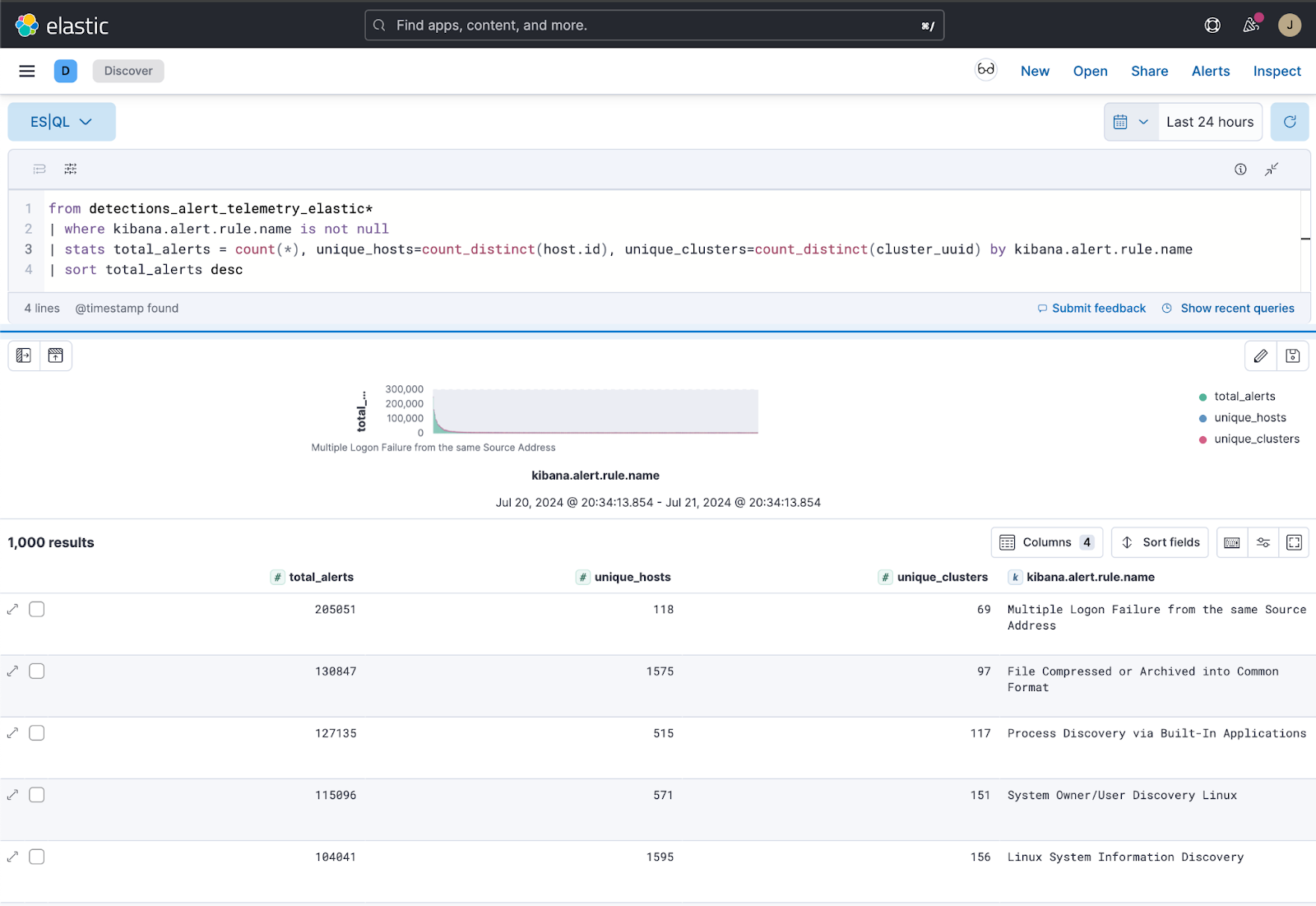
Fig. 39 Distribution of alerts by rule name over 24 hours#
Operational teams will be focused on triaging and analyzing the results, and moving to incident response if the need arises. Product teams will need to aggregate the results and determine what may be accurate in terms of results and also assess if the magnitudes are aligned with expectations, paying special attention to spikes that could indicate a false positive issue or even a surge in the legitimate success of a certain technique.
A well-developed rule capturing malicious activity that just triggers too often may be worse than a rule that triggers less often, but at the most common stovepipe (ensuring it is not missed in either scenario). This change would help drastically with controlling for alert fatigue, especially if the same principle is applied to the entire rule set, in a regular cadence.
Monitoring can also occur via other sources, such as public repos, slack channels, or discussion forums in the form of feedback. Community collaboration is continuing to grow, and there are valuable insights across the industry, even if the specific platform being discussed may be different.
Observations from this step, regardless of the source, will play an important role in the final step of the DCDL, as well as throughout the continued progression across this cyclical process. Maintaining rules and other detection capabilities is a continuous process, with this feedback being one of the most important factors, along with additional research findings, to keep rules healthy and relevant.