Elastic SIEM and EDR Rules Internals#
Brief overview of the SIEM ecosystem#
Fig. 55 Elastic SIEM components#
The core components of the Elastic stack include Elasticsearch for storage and searching, Kibana for visualizing and analyzing, and the Elastic Agent for collecting and shipping. Beats still exist as an option for collecting data, however, that will be out of the scope of this chapter, along with Logstash.
The Elastic Agent takes a fundamentally different approach than the beats-based ELK stacks of old. It is essentially a management agent intended to unify disparate agents and data collectors, With Fleet acting as the server orchestrating communications and configurations with the stack, the architecture and approach have evolved in major ways.
Integrations are built on top of the Elastic Agent, Fleet, and other pieces of the stack. One of these integrations is Endpoint Security, which is built around the endpoint agent. Like all other integration data collectors, this endpoint agent is enabled within the Elastic Agent (not as a separate installation).

Fig. 56 High level architecture of an Integration#
Within Kibana is the security solution, which houses many powerful features enabling a layered approach to security. A foundational component housed within is the detection engine, which drives the rules-based approach within the stack, and is built on top of Kibana and Elasticsearch. This is a primary piece of the SIEM and analytics features within the security solution and the core focus of this guide (though not exclusively limited to it).
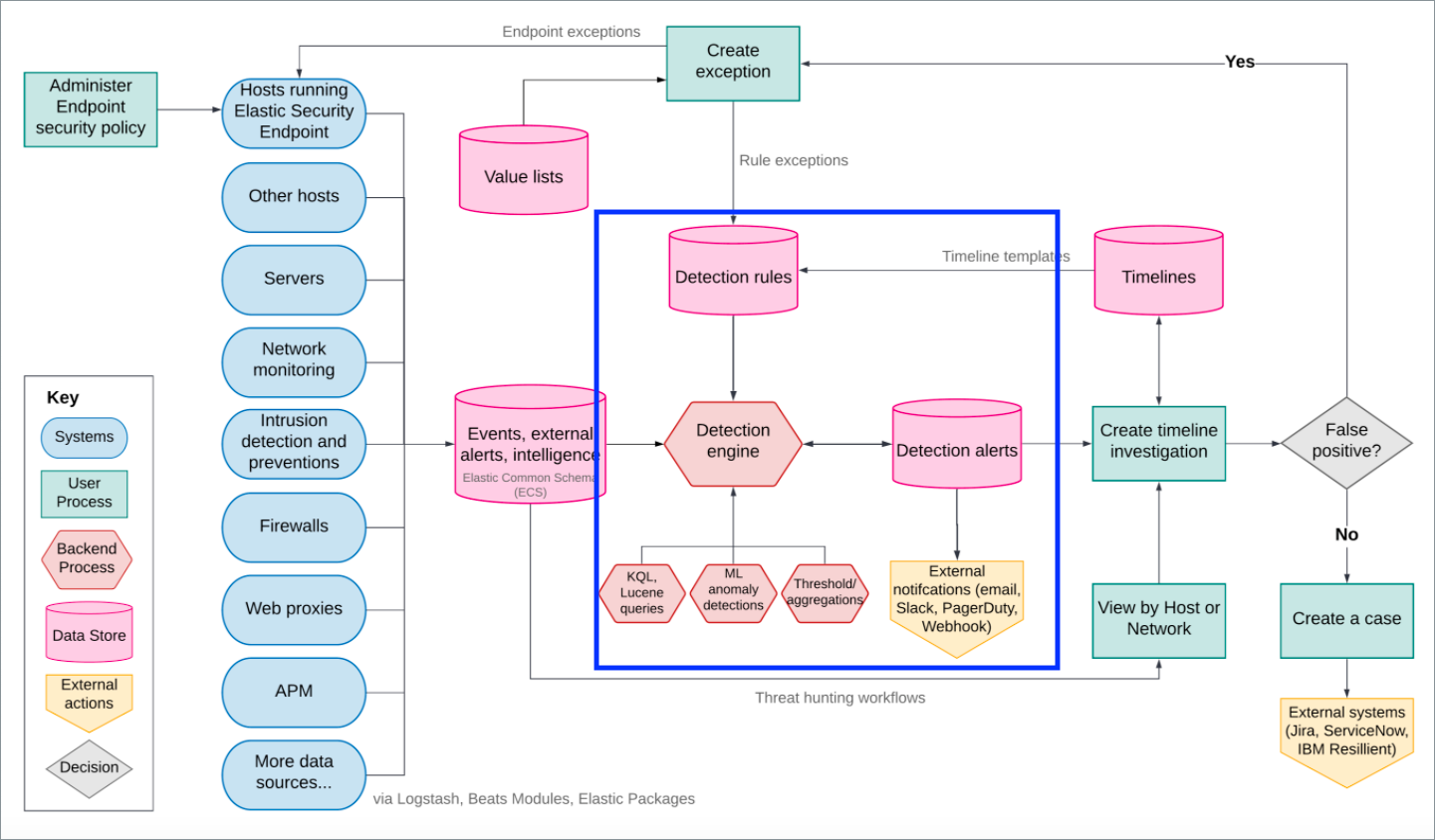
Fig. 57 Diagram of security workflow, highlighting the detection engine and rules#
The detection engine supports several different rule types, built for specific approaches. Additionally, the different rule types allow for multiple languages in various ways across the rules, including KQL, EQL, ES|QL, DSL, and Lucene. The primary focus of this guide will be ES|QL, EQL, and KQL, with some smaller references to the others. All of this will be elaborated on in the next section. ES|QL is a piped language, and so many of the concepts will feel familiar to other piped languages such as Kusto Query Language and Splunk Processing Language.
Coupled with the detection engine is a large set of prebuilt SIEM rules, providing coverage on endpoints, cloud workloads and services, network, SaaS, and many other technologies, across multiple data sources and integrations.
Elastic Security Labs performs extensive research, performs detection engineering, and develops and maintains multiple rule sets, while regularly openly collaborating with the security community.
Brief overview of Endpoint Security and EDR behavior rules#
You may have seen the announcement where we opened up more of our protections artifacts, which included the EDR behavior rules. It is important to distinguish the two different rulesets in terms of their implementations and environments.
Separate from the stack-based detection engine described above is a rules engine that is built natively within the EDR agent. This engine uses a single rule type and language (EQL). Due to the nature of the different implementations, there are slight differences in the features of Elasticsearch EQL vs endpoint EQL.
This guide will focus primarily on the stack detection engine, but will make references, recommendations, and clarifications specific to the endpoint EDR engine as appropriate. For the sake of clarity, the rest of this guide will refer to the SIEM detection engine solely as “detection engine” and the endpoint based engine as the “EDR engine”.
SIEM rules#
There are seven rule types within the detection engine:
Type |
Languages |
Description |
|---|---|---|
Custom query |
KQL, Lucene |
Alerts based on a matching query |
Event correlation |
EQL |
Alerts based on a matching EQL query, where events can be correlated within the logic |
Threshold |
KQL |
Alerts when the number of times the specified field’s value is present and meets the threshold during a single execution |
Indicator match |
KQL |
Alerts when Elastic Security index field values match field values defined in the specified indicator index patterns |
Machine learning |
N/A |
Alerts when a machine learning job discovers an anomaly above the defined threshold |
New terms |
KQL |
Alerts for each new term detected in source documents within a specified time range |
ESQL |
ESQL |
Alerts when the specified ESQL query is matched, generating individual alerts for each row |
With the exception of machine learning and ES|QL, all rule types searches are restricted to the defined indices or data view (machine learning jobs define indices to refine the scope). ES|QL defines the targeted data sources within the query itself. In addition to the specific configurations of each rule, they all also expose filter searching, via DSL, to further refine the search criteria.
Promotion rules#
The documentation will also refer to promotion rules, which are simply rules which take incoming events that are intended to be “alerts” per their source, which are formally converted to SIEM alerts. Custom query and event correlation rules allow for the defining of several *-override fields, which allows the field to be dynamically populated based on the configuration criteria. That functionality is leveraged to translate the source alert name into the generated SIEM alert name, along with information in the other override fields.
These are most commonly employed on processed alerts or third party data, where the source information is likely already alertable on its own. An example is the promotion of alerts from the Elastic endpoint security features to show up as a detection alert. A series of raw promotion alerts can be seen within the repo. This specific example takes the value in the message field and stores in in the alert name for corresponding alerts due to the definition:
rule_name_override = “message”
Building Block Rules (BBR)#
Building block rules are configured identical to any of the valid rule types, but are configured with a special building block boolean field to specify it as such. The primary functional difference vs a normal rule, is that these rules will not be shown in the alerts table, but solely written to the alerts index. This is intentional to all certain docs or data to be labeled and leveraged for future reference with this additional context. A common mechanism to leverage this functionality is to build “rules on alerts”, where the specified target index is the alerts index. These may sometimes be referred to as “higher order rules”.
Prebuilt and custom rules#
Lastly, there are prebuilt rules and custom rules. Prebuilt rules are the rules which are packaged with Kibana and managed by elastic, whereas custom rules are user defined and managed within the UI. All rule types are compatible with both pre-built and custom rules.
Fig. 58 Rule interface with toggle between pre-built and custom rules highlighted#
EDR rules#
As mentioned previously, the endpoint EDR engine only has a single rule type which uses EQL as the query language. The implementation difference has led to some minor differences in the language. Where relevant, such differences will be highlighted.
A big difference when compared to the detection engine is the scope of the data being processed. Since the engine is
implemented within the sensor, it only processes the data of a single system. Additionally, it processes the data inline
(vs batch processing of the detection engine). This enables the feasibility of certain functionality to performantly
work within the endpoint that may be much more difficult (or not make sense to do) in the detection engine. An example
of this is determining ancestry, which in EQL parlance is searched via descendent of.
Consideration when choosing SIEM rule types#
Choosing the best rule type for a given situation may not always be obvious. Oftentimes it can be very circumstantial, based on the data, the rule author, the behavior to detect, available resources, and many other factors. Likewise, the language used is not just a matter of linguistic preference, but is usually based on the nuances of each language and their capabilities (such as controlling for case sensitivity in EQL independent of the data).
ES|QL rules are perfect when aggregations need to be performed, but they also have many additional benefits. The ability to set variables and pipe intermediate functionality allows for more control over the reduction of search matches. Finally, it also allows for more granular control of alerts generated, since each row creates an alert. This allows for control of result counts by limiting, deduplicating, or aggregating.
Custom query rules are the simplest rule type, which is usually the most common reason for choosing that rule type. If the data is simple and straightforward with no need to do complex checks, then this is a good choice. User familiarity with KQL (and Lucene) is a major advantage for choosing this rule type. Compatibility with the discover interface and the prevalence of KQL-compatible search bars across Kibana also add strengths to choosing this type.
Event correlation rules are very similar with the primary difference being the use of EQL. An obvious reason to use EQL would be the ability to use sequences to correlate across multiple documents (and sources). Some other not so obvious reasons to choose this rule type are:
Improved readability
Controlling for case sensitivity within the query using
:or the~decoratorAdding comments within the query to annotate specific usage
Using regex (without having to use Lucene)
Using wildcards without the need to escape special chars (such as in KQL)
Having access to a bunch of functions to enhance search capabilities
All of these specified features are also available in ES|QL, though some with different syntax or names.
Threshold, indicator match, and new terms rule types use cases are much more obvious due to the specific nature of their capabilities. Threshold rules are another way to correlate data across multiple sources and can be very powerful in finding things such as brute force attacks. Indicator match is a great way to take advantage of threat intel feeds and other processed data sources. The newer rule type new terms rule type can be especially powerful in organizations that have a good baseline of their environments to identify unexpected activity.
Lastly, the machine learning rule type is only usable to turn machine learning jobs into alerts. While this is out of the scope of this guide, these jobs and other machine learning features within the stack are incredibly powerful ways to supplement rules for a more robust detection capability.
For inspiration or insight into the rule types leveraged per specific use cases for Elastic developed rules, you can use GitHubs advanced search to specify the type.
An even better option would be to use the rules repo CLI, where you can leverage EQL/KQL to search the rules themselves!
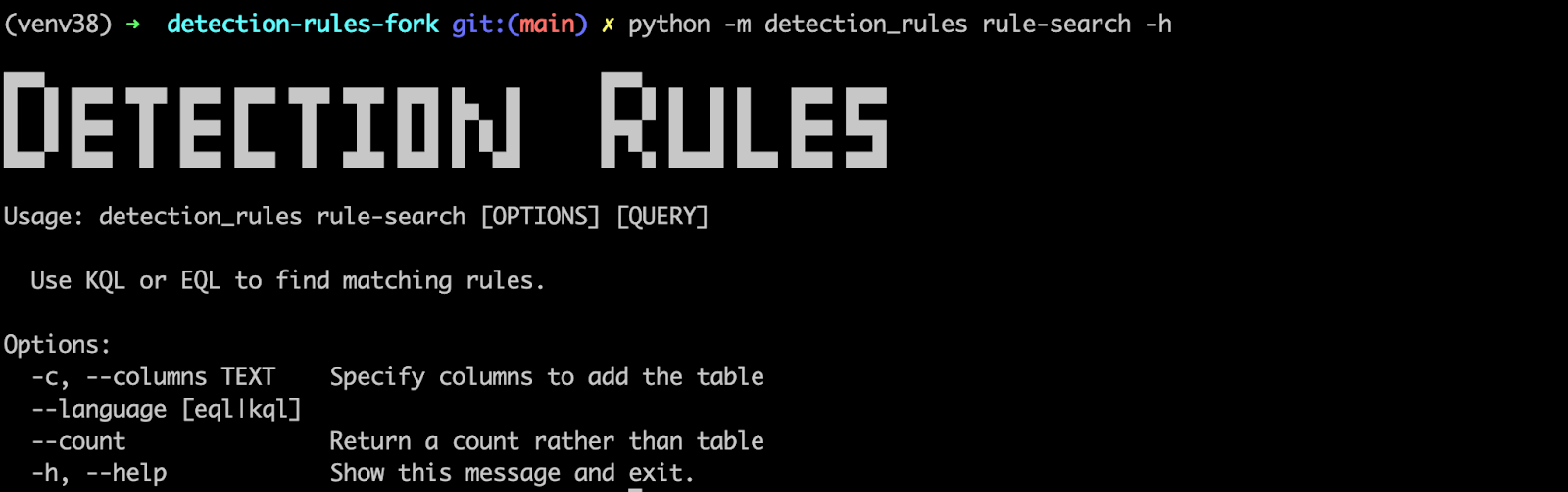
Fig. 59 SIEM rules CLI to perform advanced searches into the rule set - help#
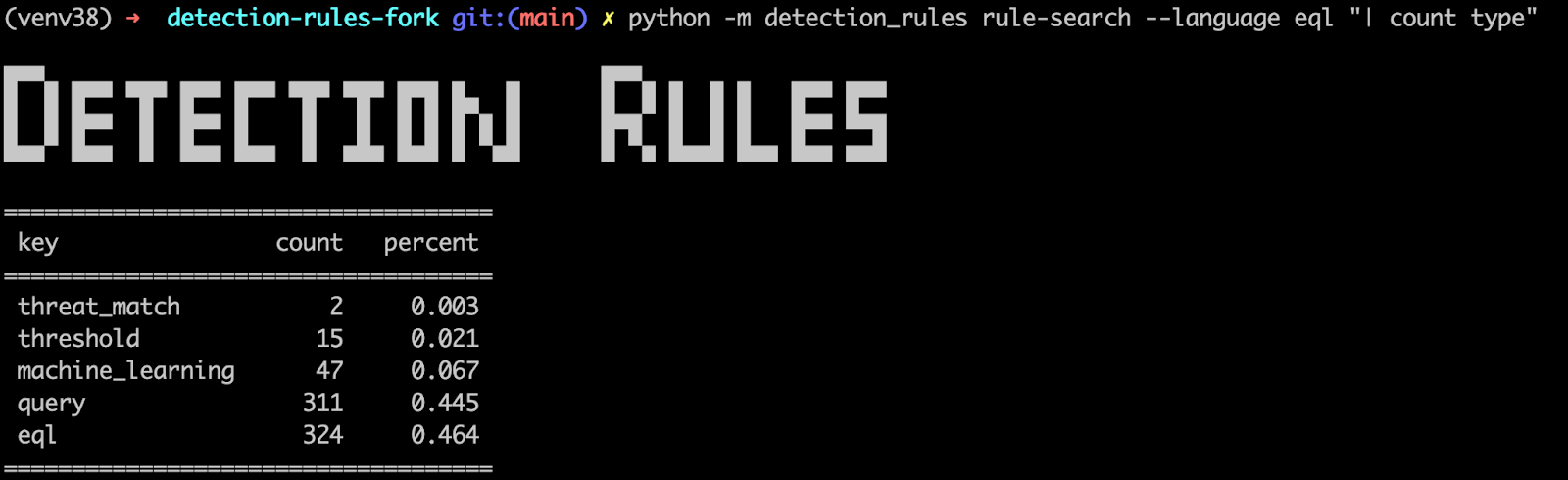
Fig. 60 SIEM rules CLI to perform advanced searches into the rule set - summary#

Fig. 61 SIEM rules CLI to perform advanced searches into the rule set - details#
Insights on when SIEM vs EDR rules are chosen by Elastic researchers#
The greatest deciding factor between a SIEM or EDR rule is whether or not the behavior can be prevented (by killing the
process, etc.), which would be based on a very high confidence on a very specific behavior with a low precedence of
false positives (FP). Next biggest considerations are whether any of the endpoint specific EQL functionality is
required to detect the activity (such as descendent of).
Lastly, some features of detection rules make them much more conducive to certain approaches:
They are forkable (copy rule)
They are tunable (custom or forked)
They can be enabled/disabled individually
They are detection only, so FP has no chance of killing an FP process
These are just a few factors which make detection rules a good option when confidence of a behavior is not fully established, or when noise tolerance needs to be higher. Essentially, they can be a more forgiving approach. It is also fairly common for identical or similar rule logic to target both SIEM and EDR.
Understanding the composition of a rule#
Most of the rules are composed of metadata and a query. The metadata is made up of multiple key value definitions, some of which are optional. Some of the metadata is purely informational, while others have a direct impact on the rules themselves, with implications on performance and efficacy.
For a detailed description of rule composition, refer to chapter 6, section 3b.