Performance#
Writing effective queries for optimal searches#
EQL vs KQL#
Under the hood, EQL builds DSL for its search, and for more complex features, it relies on painless scripting. Underneath all of it is its dependency on Lucene. KQL also builds DSL and is reliant on Lucene. So when comparing the performance differences between the two, it is best to focus on where they diverge. Performance-wise, KQL will usually be the stronger choice.
Leveraging filter queries#
As mentioned earlier, most of the rule types expose filter queries in addition to the supported query search. In a normal search within elasticsearch, here are some differences between a query and filter search:
It is recommended to use filters as much as possible
Filter searches skip the score calculation, which is faster
Frequently used filters can be cached
Query focuses on: How well does the document match this query?
Filter focuses on: Does the document match this query?
Additional considerations and best practices#
Follow established query patterns that are known to be performant (this also adds consistency to make rules more understandable!)
Ex: leverage
process.entity_idvspiddue to risk of reuse
Consider the Impact of the size and shape of the data
Avoid runtime fields if you can, because they are computationally expensive
Fix data at ingest time instead
Better to use ES|QL!
Avoid errors by checking for null or empty values
Use the security rule preview pane to get a sense of noise and magnitude
Understand when to use different field types such as text vs keyword vs wildcard
Understand when to leverage text composedanalyzers to save search time, but also the expense at ingest
Unnest complex structures
Understand when to ingest with and search with multi-fields
Minimize wildcard search usage to the extent possible, but especially the use of leading wildcards
Take advantage of single character wildcards
?Leverage the wildcard type for fields that are often searched with wildcard
Regex can be more performant than wildcards if the patterns are crafted well
In reality, there are so many overlapping considerations that it ultimately depends on many environmental factors. Here is a reference Elastic guide for optimizing the environment for maximal search efficiency and speed.
The most definitive way to determine what performs best within a specific environment is to test and benchmark as often as possible. Leverage the search profiler to simplify this process.

Fig. 62 Search profiler in Kibana under dev tools#
If really curious, you can also consult the open nightly benchmarking dashboards for Elasticsearch here or here, or even consult some of the test queries.

Fig. 63 Elasticsearch nightly benchmarks#
Rule optimizations#
This section will focus on ways to optimize performance of rules outside of modifying the search query itself. Namely, focusing on the implications of values within specific metadata fields.
from#
This defines the start of the window for the search range for every rule execution (default value is now-6m). A larger
window per search results in processing more data. This should be balanced with the interval for performance and
completeness.
to#
This defines the end of the window for the search range for every rule execution (default value is now). The to - from
is sometimes referred to as the lookback (lookback window or just window). It should be very rare to modify this value
from the default, but if so, should be accounted for with the interval.
interval#
This dictates the interval between each rule search execution. This should be balanced with the lookback. Oftentimes the rate of the source data being ingested has the biggest impact on this field. To the extent that the rate is modifiable, the interval should be adjusted thereafter. It should be wide enough to occur after the average batch arrives, but not overly so. The lookback should account for the gap with some overlap (at least 1m). The detection engine has deduplication logic to handle the overlap.
max_signals#
This limits the number of alerts that will be generated per each rule search execution (the default value if undefined is 100 rules). For really noisy rules, this could help limit the impact of processing the triggered rules.
maxspan#
This is not actually a metadata field, but a piece of an EQL sequence search. It is included here for its relevance in deciding on an optimal lookback and interval. There is a relationship between the maxspan, lookback window, and interval which should be maintained. If one of these fields exceeds the threshold either way, the query runs the risk falling out of balance.
index specificity#
Reduce index patterns as much as possible as allowed by the documents being searched. This will tighten the scope of the
search. Instead of logs-*, do logs-endpoint.events.process*.
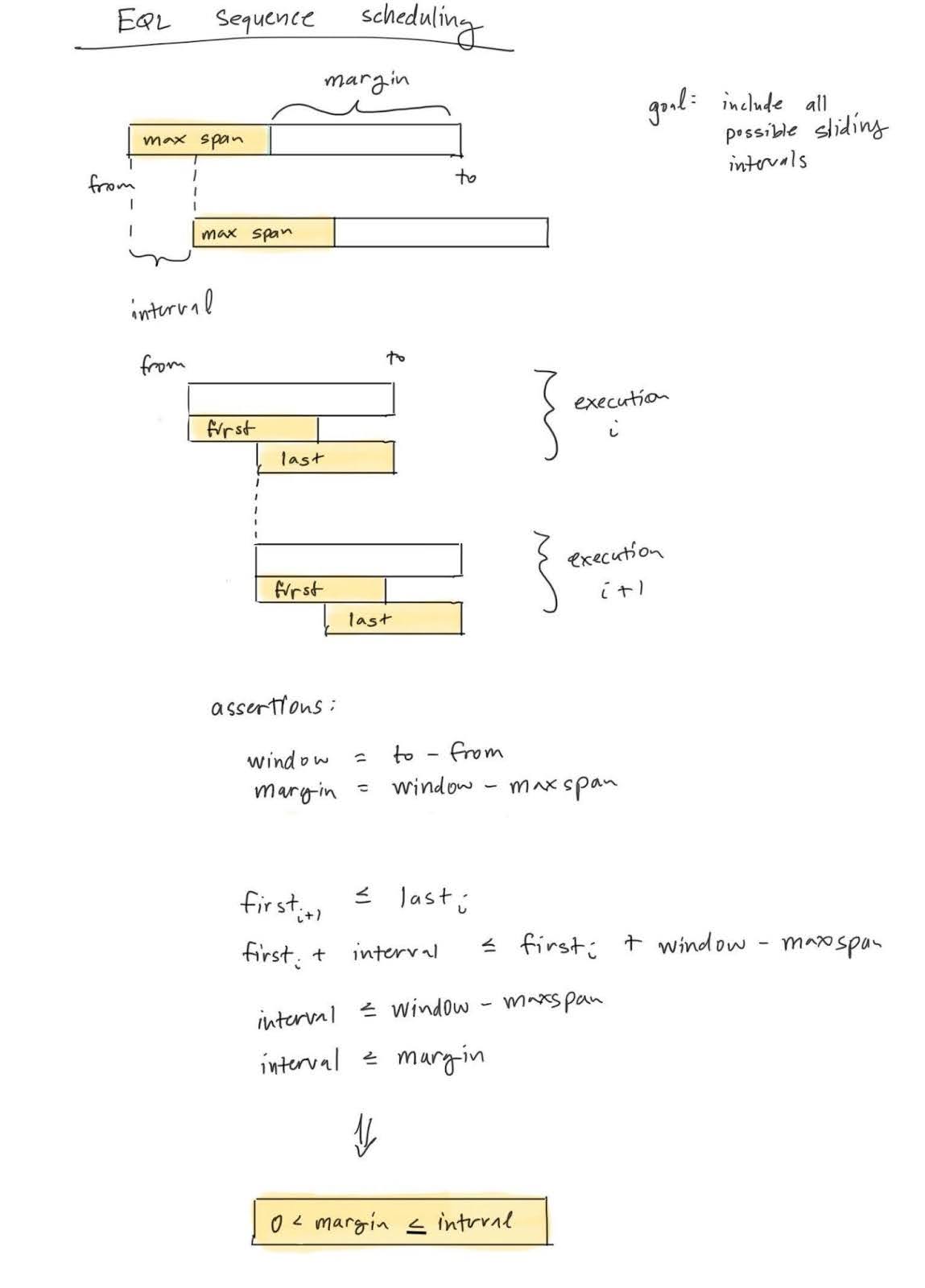
Fig. 64 Notes on EQL sequence scheduling (by EBDFL-RW)#
All of these fields can have a significant impact on the performance of a rule and the detection engine as a whole. Overfitting can result in inefficient use of resources while underfitting can quietly lead to incompleteness of rule executions leading to false negatives from excluding data across searches. In general, it is usually safest to rely on the defaults, but this can be challenged by non-normal data sources.
Cumulative performance observations and methods for testing#
To keep an eye on the entire rule set, you can leverage the built in rule monitoring
feature.
You can also leverage the rule monitoring dashboard for even greater detail and visualizations. For the most advanced
use cases, you can also leverage the index .kibana-event-log to search directly or build custom dashboards.
For a detailed breakdown of rule rule testing and considerations, refer to chapter 6, section 3b.

Fig. 65 SIEM rule monitoring page#

Fig. 66 SIEM rule monitoring dashboard#