Efficacy#
Efficacy is concerned with whether a rule achieves its intent by generating the most accurate, concise, and balanced alert as possible. It should be considered in the context of the entire rule set as well.
Balancing the scope of a rule is paramount. Trying to detect every single variation of a technique within a single rule can make effectively handling the alert more difficult. Overscoping usually results in adding a bunch of exceptions to a rule in order to tune out the false positives, while trying to match every true positive. Specterops does a good job capturing the essence of this with their Detection Spectrum.

Fig. 67 A spectrum of specificity#

Fig. 68 An atomic vs comprehensive approach to detection logic#
The progression of activity should also be well balanced. This means that if you wanted to detect A -> B -> C -> D,
then maybe it is better off in separate rules, such as A -> B and C -> D. Being too comprehensive here can create
brittleness. The opposite of highly-correlated would be taking an overly atomic approach, where singular IOC’s or being
searched, in more of a signature-based approach.

Fig. 69 Partitioning logic to break out into individual rules#
Ultimately, the best determination of efficacy is to understand the accuracy of a rule, the resulting “noise” of false positives, and how it aligns with acceptable tolerances. The best way to assess this is by leveraging a confusion matrix, with slight variations, where in this case, our predictions are based on rule criteria successfully matching and the actual outcomes are represented by the creation of alerts.
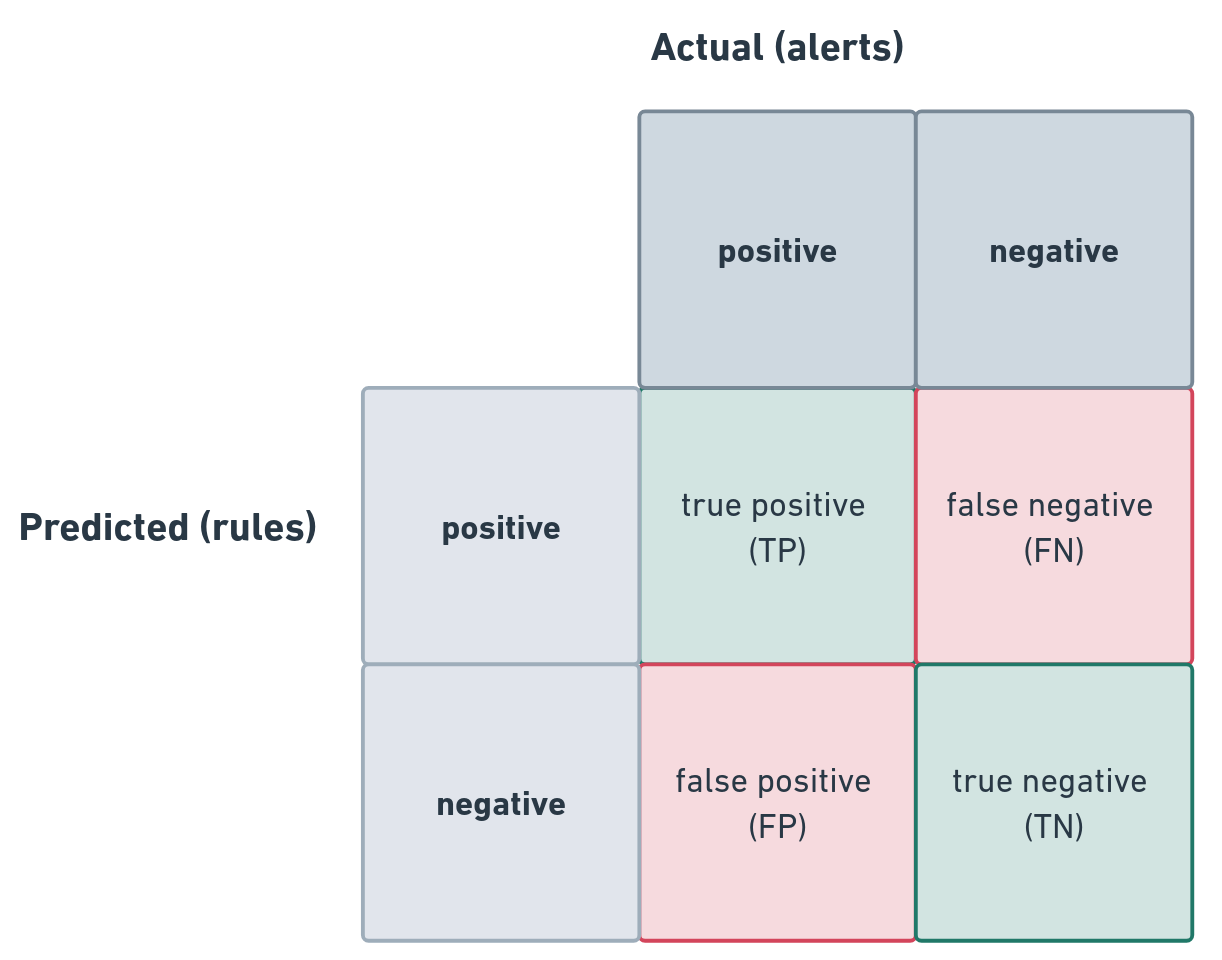
Fig. 70 Modified rule confusion matrix#
The reality is that it is almost impossible to truly account for all FN (or often accounting for any). Similarly, true negative doesn’t completely apply in the same way as the original intent of such matrices, at least not at the individual occurrence level. True negative as a metric is more valuable in what it implicitly conveys – the lack of false positives (possibly as a volumetric perspective). This results in most of the analysis and control focusing around TP and FP.
This isn’t an exact science at this point, due to the problematic nature of TN and FN in this regard, which is why it is usually based on tolerance for the noise of FP and the implications of FN, which is usually detected via triage or analysis of separate activity, downstream of the miss. The most commonly defined tolerance metrics are around FP, but again, this is likely a reflection of the fact that they are measurable and undesirable.
It is less common to see TP thresholds defined, but those can be just as informative, based on some of the previous discussion. Beyond cases where the occurrence of the TP actually reveal compromise by an unexpected threat, high TP rates could imply that a rule is too atomic, too minimally scoped, or even that it may not be the best thing to alert on.
Due to the immeasurability and lack of definitiveness with FN and TN, it is not really feasible to measure the commonly associated attributes of accuracy, recall, and sensitivity, however, precision is much easier to measure using: TP / (TP + FP). So, 20 TP and 80 FP results in a 20% precision rate.
Zach Allen did a good job previously capturing some of this in a series of tweets.
So, to summarize some of the measurables:
High FP rates, overall and per rule may indicate the need to tune or remove a rule
Unexpectedly high TP rates may indicate the need to rescope a rule
Low precision rates indicate the need to tune or remove a rule
High occurrences of indirectly observed FN indicates the need to tune the rule
A lack of alerts doesn’t verify TN but could indicate FN, which can be controlled with randomized testing